
当社では社内でNOC(Network Operation Center)を組織して運営しています。
SIしたシステムの運用を請け負っている他、過去にはMVNOインフラをSaaS風のプラットフォームとして提供する「わくわくモビリティ(2022年12月にサービス終了)」でもシステム運用を行ってきました。今回はNOC運営経験をもとに、これまで取り組んできた改善方法についてご説明します。
目次 非表示
従来の運用フロー
一般的な対応ですが、おおよそ以下のような段取りで対応を行っていました。
- 被監視システムで障害発生
- 監視システムで障害の発生を検知、NOCへメールでアラートの発生を通知
- NOCに設置してある赤色回転灯が点灯、NOCへ詰めている保守者(Tier1)が対応を開始
- 保守者(Tier1)はアラートの通知内容からメンテナンスの有無、障害対応手順を検索
- 発生したアラートに対して障害対応手順が準備されている場合はこれに従って措置
- 障害対応手順による措置が有効でなかった、あるいは、障害対応手順が存在しない場合は保守者(Tier2)へエスカレーションを行うため、アラート発生源の保守者(Tier2)を待機シフト表から検索
- 待機シフト表に定義された順番に保守者(Tier2)へ電話でエスカレーション、最初に連絡のついた保守者(Tier2)が対応を開始
- 保守者(Tier2)でも対処不可能な場合は、さらに上位SEやメーカへエスカレーションして対応
従来の運用フローの問題点
被監視システムのSLAにもよりますが、24×365でNOCを運営するとなるとTier1の人的なリソースだけでも1日あたり6人日程度は最低限必要です。監視しているシステムの規模や数によってはさらに人員の増強が必要ですし、現実的にはメンバーの体調不良や休暇で発生するシフトの欠員を埋めるための人員確保がさらに必要です。
システムがある程度の規模になると、Tier2へのエスカレーション先が障害の発生源によって変わることがしばしば発生します。インフラ部分はAさんとBさん、アプリケーション部分はCさんとDさんといった具合です。
通常、これに加えて曜日や時間帯に応じてエスカレーション先が変わることになるため、Tier1の担当は複雑なシフト表からエスカレーション先を判断することになります。しかし常にアラートの発生源がエスカレーション先になるとも限らず、アプリケーションがDBの接続エラーを検知した場合はインフラ担当へのエスカレーションを行う、といった例外的な対応を要するケースもあり、不慣れなメンバーではエスカレーション先の選択を誤ってしまうこともあります。
また、Tier1はTier2と比べて構成員が若手であったり、経験が少ないメンバーが比較的多い傾向があると思います。このような体制を組んでいるチームでは、Tier1がTier2へのエスカレーションをためらってしまうという事故が起き得ます。
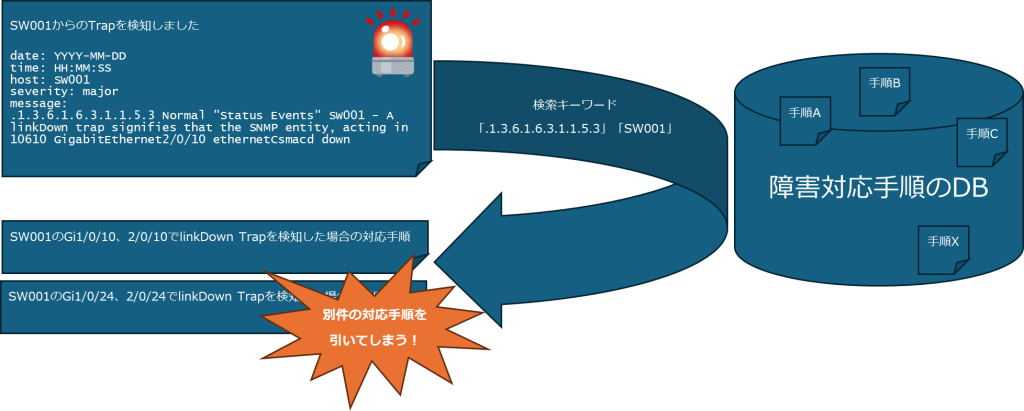
従来の運用フローの4項目に「障害対応手順を検索」とサラっと書いてありますが、システムに熟知していない保守員がアラートとして通知されるログから対応手順の検索に使うべきキーワードを切り出すのは思いのほか難易度の高い作業です。キーワードを取り違えた結果、対応手順も取り違えてしまう、あるいは対応手順が見つからない、といった結果になるケースがあります。
簡単な例を挙げます。
linkDown Trapをsnmpttに翻訳させたログでは以下のような文字列がアラートとして可視化されます。
.1.3.6.1.6.3.1.1.5.3 Normal "Status Events" hostname - A linkDown trap signifies that the SNMP entity, acting in 10610 GigabitEthernet2/0/10 ethernetCsmacd downここで障害対応手順を検索する際に使用するキーワードは何が適切でしょうか?
様々な流派はあると思いますが、最低限以下は選択されるべきです。
.1.3.6.1.6.3.1.1.5.3 → Trapの種別(linkDown)を示すOIDhostname → Trapの発生源(ホスト名)GigabitEthernet2/0/10 → Downしたポート
こんなことは常識だよね?と感じる方もいらっしゃると思うので少しだけ難易度を上げてみましょう。
以下はActiveLogic Networks社(旧Sandvine社)の機器がストレージ障害を検知した場合に発せられるTrapをsnmpttに翻訳させた文字列です。
.1.3.6.1.4.1.15397.2.8.4.4 Normal "Status Events" hostname - 0: State change on PD 02(e0x20/s2) from ONLINE(18) to FAILED(11) Device ID: 2 Enclosure Index: 32 Slot Number: 2 Previous state: 24 New state: 17 majorこれはSandvine社のさらに前身であるProcera Networks社により定義されたベンダーMIB(enterprises.15397)内で定義されるTrapであり、インターネット上に流通している情報はほぼありません(なぜかMIBファイルが公開されていましたが)。
この場合、キーワードはどのように選択するべきでしょうか?考え方はlinkDown Trapと似ているのですが、以下を選択するべきだと考えます。
.1.3.6.1.4.1.15397.2.8.4.4 → Trapの種別(pl2StoragePhysicalDisk)を示すOIDto FAILED(11) or New state: 17 → 変化したステータスの状況
ここで障害の発生位置に関する情報(ホスト名やスロット番号「PD 02(e0x20/s2)」)をキーワードから抜きましたが、NW機器におけるポート番号と違い、ストレージ障害の場合はどのスロットのストレージが故障しても対応すべき措置は同じ(故障したストレージを正常な部材と交換してリビルドをかける)であるため、基本的には障害の発生位置を限定する必要性がありません。
比較的規格化されているSNMP Trapであっても、このようにTrap発生源となっている機器のメーカや障害の特性に合わせて対応することが求められます。さらにsyslog、特にアプリケーションが出力するログに至っては全く規格化が為されていないケースも多々あり、障害ログの読解に関して全てのTier1のメンバーへ教育するというのは無理があると言っても過言ではありません。
我々の打ち出した改善策
まず人為的にもミスが起きやすい問題3について手を打ちます。
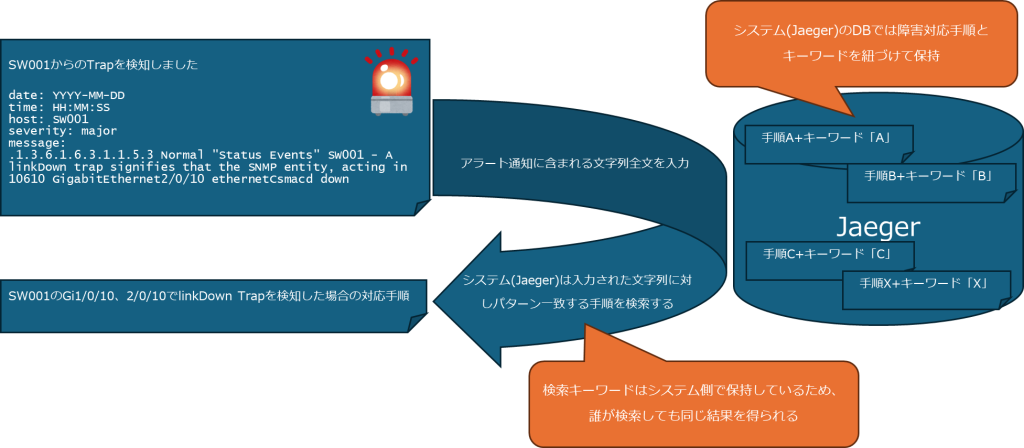
当社ではアラート通知に含まれる文字列の全てを検索パラメータとして入力することで、正しい障害対応手順を検索できるシステム(Jaeger)を構築しました。このシステムは一般的な全文検索のようなアルゴリズムではなく、入力された文字列に対して事前に定義しておいたキーワードを含むかどうか評価を行い障害対応手順を引くという特殊なもので、汎用的な実装が見つからなかったため全て内製しました。
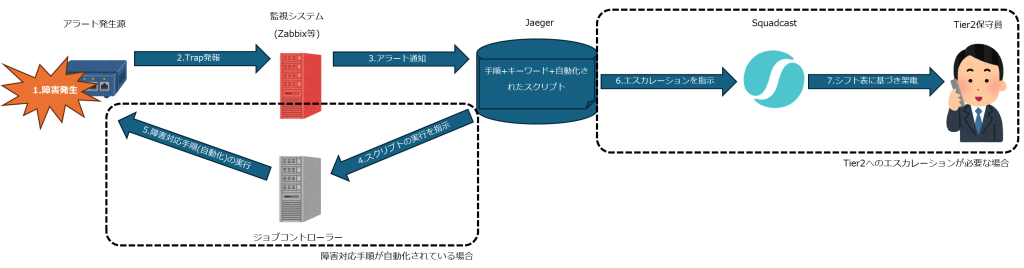
問題1、2に関してはSquadcastを導入(詳細は過去のBlog「Squadcastによるエスカレーションの自動化」「エンジニアが疲弊しないネットワーク監視の実現」をご覧ください)しTier2へのエスカレーションを自動化することで問題を緩和できましたが、このままではTier2へのエスカレーションが増えてしまいTier2の負担が増えてしまいます。
そこで障害対応手順のうち自動化の可能なものをスクリプト化しJaegerよりジョブコントローラーを介して実行できるよう機能を追加しました。これにより従来はTier1で実施していた初動の対応を自動化することでTier2へのエスカレーションを低減させています。
さいごに
当社では様々な改善を行った結果、NOC運営を大幅に自動化し、限られたリソースを有効活用できるようになりました。同じようなお悩みをもつ方も多くいらっしゃるかと思います。ぜひ当社までお気軽にご相談ください。

